Introduction to Linear Algebra
Systems of Linear Equations
- Introduction
- Linear systems
- Vectors
- Linear combinations
- Matrices
- Planes in ℝ³
- Reduced Row-Echelon Form
- Equation A x = b
- Sensitivity of solutions
- Linear independence
- Plane transformations
- Space transformations
- Rotations
- Linear transformations
- Affine maps
- Exercises
- Answers
Matrix Algebra
- Introduction
- Manipulation of matrices
- Partitioned matrices
- Block matrices Matrix operators
- Determinants
- Cofactors
- Cramer's rule
- Equivalent matrices
- Elimination: A = L U
- PLU factorization
- Reflection
- Givens rotation
- Special matrices
- Exercises
- Answers
Vector Spaces
- Introduction
- Motivation
- Vector spaces
- Bases
- Dimension
- Coordinate systems
- Change of basis
- Linear transformations
- Matrix transformations
- Compositions
- Isomorphisms
- Dual transformations
- Direct sums
- Quotient spaces
- Vector products
- Cross products
- Rank
- Solving A x = b
- Exercises
- Answers
Eigenvalues, Eigenvectors
- Introduction
- Characteristic polynomials
- Companion matrix
- Algebraic and geometric multiplicities
- Minimal polynomials
- Eigenspaces
- Where are eigenvalues?
- Eigenvalues of A B and B A
- Generalized eigenvectors
- Similar matrices
- Diagonalizability
- Self-adjoint operators
Euclidean Spaces
- Introduction
- Dot product
- Bilinear transformations
- Inner product
- Norm and distance
- Matrix norms
- Dual norms
- Dual transformations
- Orthogonality
- Gram--Schmidt process
- Orthogonal sets
- Self-adjoint Matrices
- Unitary matrices
- Projection operators
- QR-decomposition
- Least Square Approximation
- Quadratic forms
- Exercises
- Answers
Matrix Decompositions
- Introduction
- Symmetric matrices
- LU-decomposition
- QR-decomposition
- Cholesky decomposition
- Schur decomposition
- Positive matrices
- Roots
- Polar factorization
- Spectral decomposition
- Singular values
- SVD <
- Pseudoinverse
- Exercises
- Answers
Applications
- GPS problem
- Poisson equation
- Graph theory
- Error correcting codes
- Electric circuits
- Markov chains
- Cryptography
- Wave-length transfer matrix
- Computer graphics
- Linear Programming
- Hill's determinant
- Fibonacci matrices
- Discrete dynamic systems
- Discrete Fourier transform
- Fast Fourier transform
- Curve fitting
Functions of Matrices
- Introduction
- Diagonalization
- Sylvester formula
- The Resolvent method
- Polynomial interpolation
- Positive matrices
- Roots <
- Pseudoinverse
- Exercises
- Answers
Miscellany
- Circles along curves
- TNB frames
- Tensors
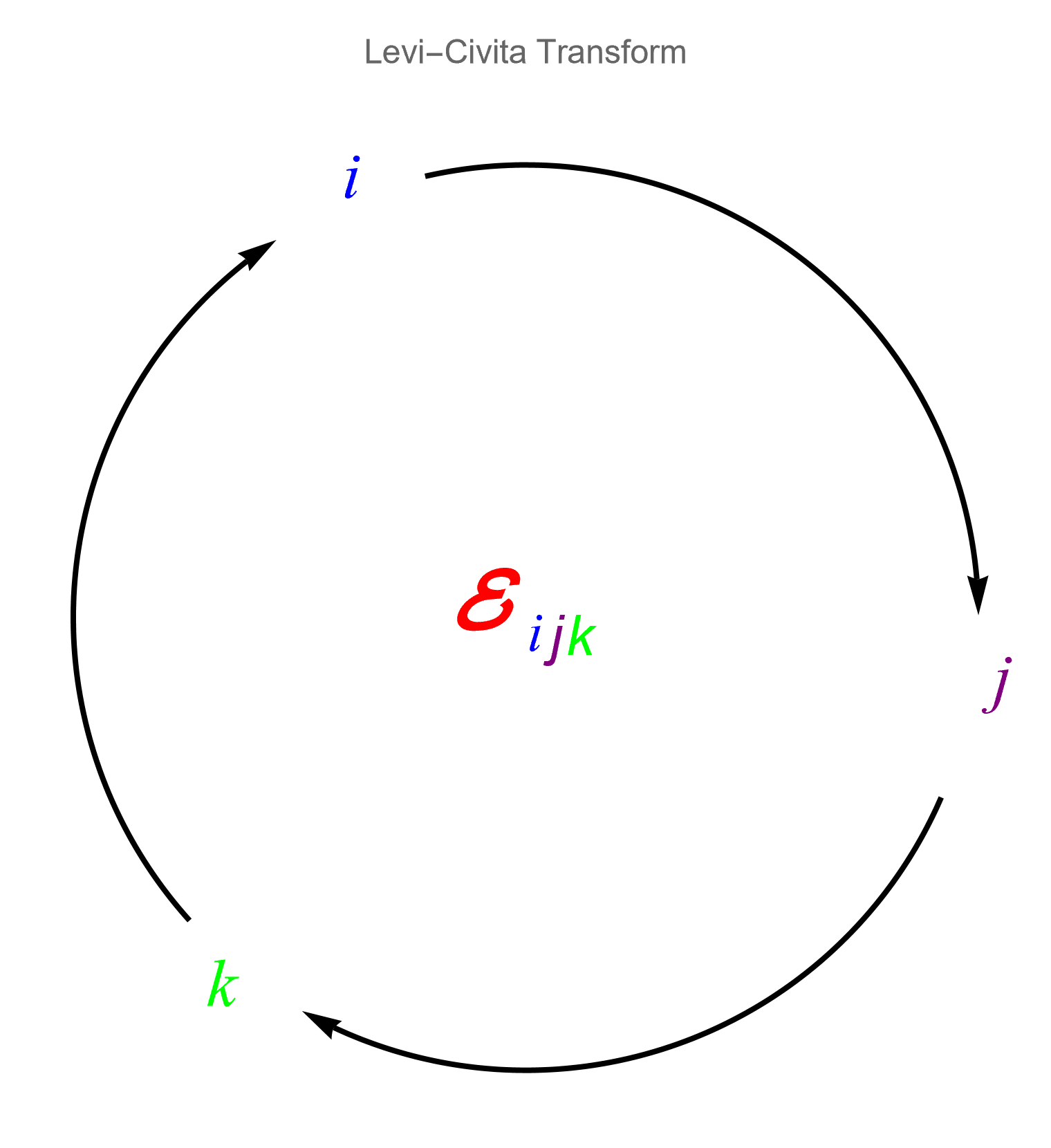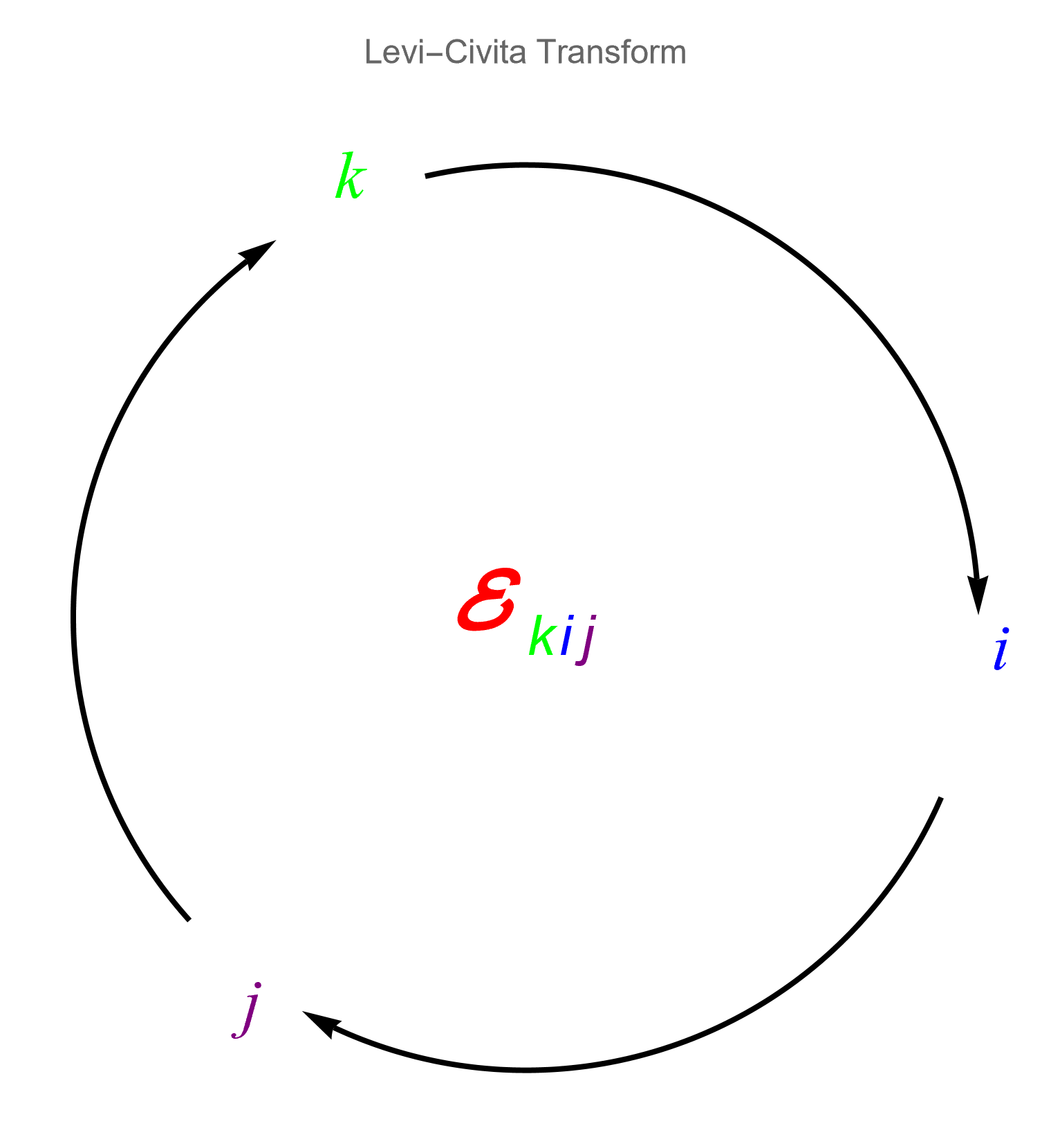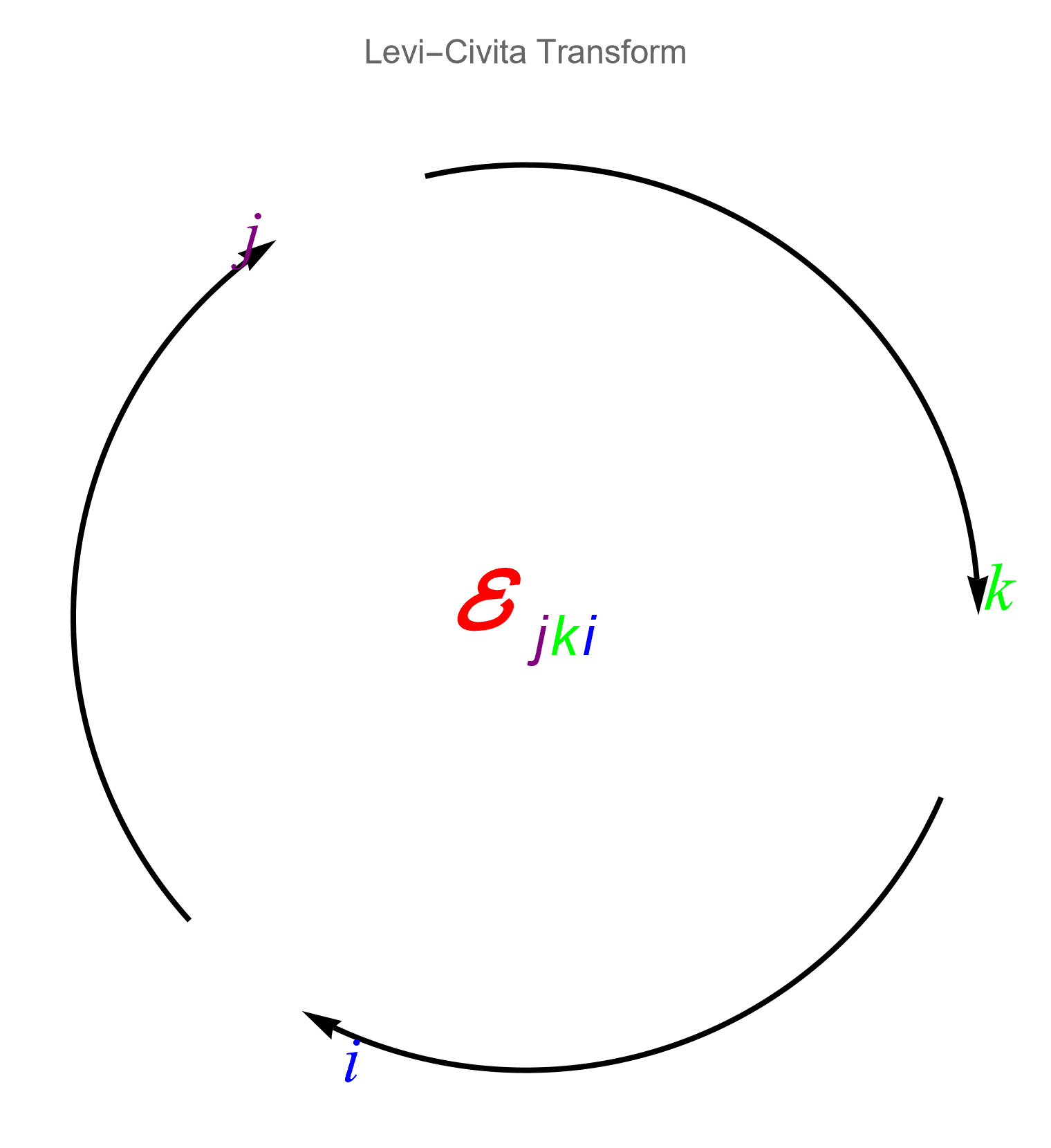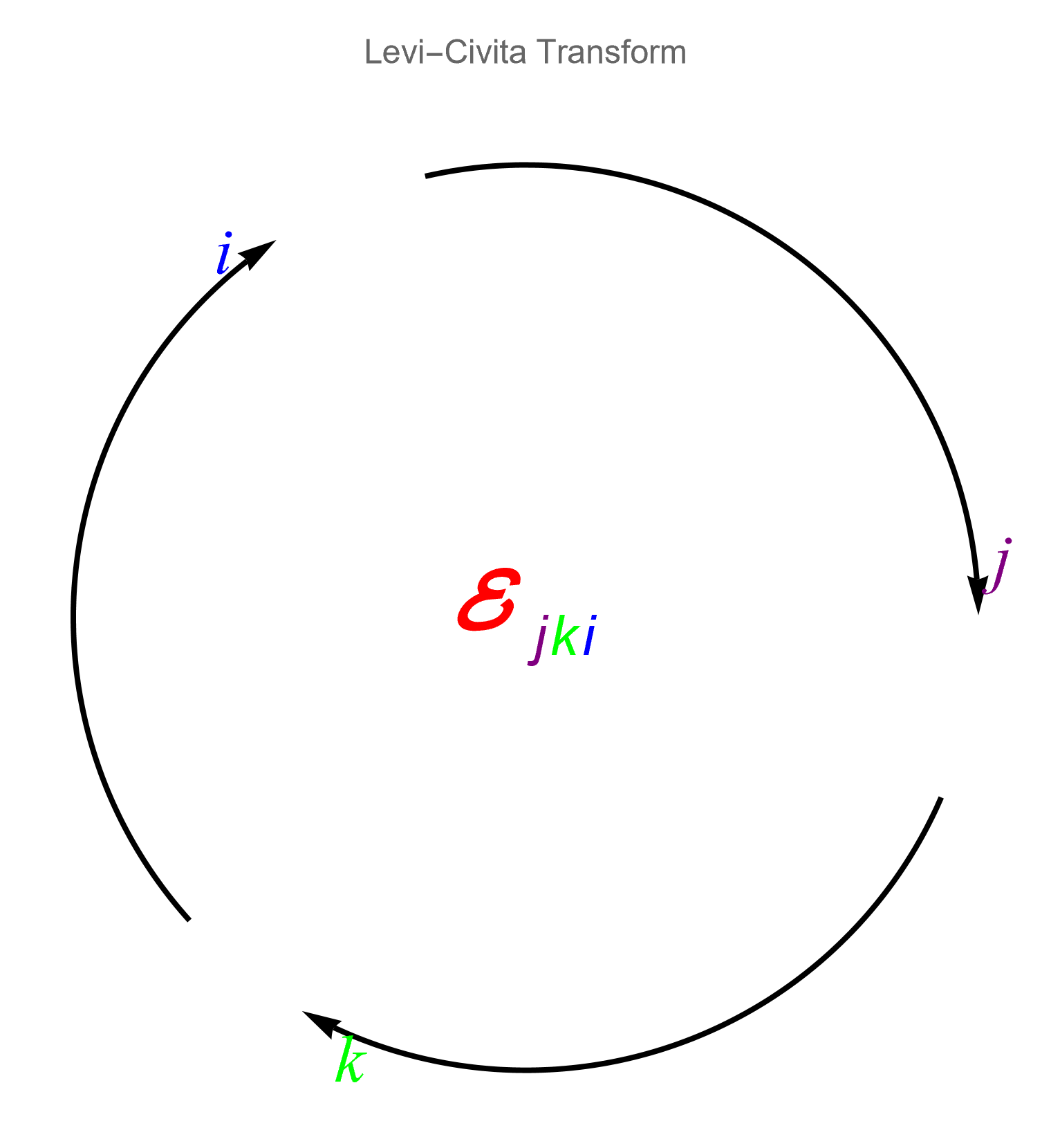
- Tensors in ℝ³
- Tensors & Mechanics
- Differential forms
- Calculus
- Vector Representations
- Matrix Representations
- Change of Basis
- Orthonormal Diagonalization
- Generalized Inverse
- Differential forms
Preliminaries
- Complex Number Operations
- Sets
- Polynomials
- Polynomials and Matrices
- Computer solves Systems of Linear Equations
- Location of Eigenvalues
- Power Method
- Iterative Method
- Similarity and Diagonalization
Glossary
Reference

This Book is licensed under Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License
Not all square matrices are diagonalizable, which means that they are represented in the form A = SΛS−1 for some diagonal matrix Λ and invertible matrix S ∈ GLn. Fortunately, if you are interested in applied linear algebra, then "most" matrices are diagonalizable. "Most" is a difficult word in math, because it requies introduction of special topology in the set of square matrices (which out of the scope of our tutorial). However, it means means that most of the square matrices that show up in statistics, machine-learning, data science, computational simulations, and other applications, are likely to be diagonalizable.
Diagonalizability
Let V be a finite dimensional vector space over field 𝔽 and T : V ⇾ V be a linear transformation. We also indicate it as T ∈ ℒ(V). We analyze the situation when V has a basis of eigenvectors of T. Recall that two square matrices of the same size are called similar if there exists an invertible matrix S such that S A = B S.A = S . DiagonalMatrix[{1, -1, 2}] . Inverse[S]
- T is 𝔽-diagonalizable.
- The geometric multiplicities of the T-eigenvalues add up to n.
- V is the direct sum of its T-eigenspaces.
If we denote by σ(T) the set of all eigenvalues of matris ⟦T⟧, then \[ \left\{ \beta_{\lambda} \ | \ \lambda \in \sigma\left( T_A \right) \right\} \] is a partition on β. It follows that \[ \sum_{\lambda \in \sigma (T)} \left\vert \beta_{\lambda} \right\vert = n , \] which is to say that the sum of the geometric multiplicities of the T-eigenvalues is n. This proves that part (a) implies (b).
Next assume that (b) is true. For each eigenvalue λ in &sigma(T), let βλ be a basis for Vλ. By our assumption, \[ \sum_{\lambda \in \sigma (T)} \left\vert \beta_{\lambda} \right\vert = n , \] which implies that \( \displaystyle \quad \sum_{\lambda \in \sigma (T)} V_{\lambda} = V. \quad \) Since the sum is direct, (b) implies (c).
Finally, assume that \( \displaystyle \quad \oplus_{\lambda \in \sigma (T)} V_{\lambda} = V. \quad \) Let \[ \beta = \cup_{\lambda \in \sigma (T)} \beta_{\lambda} , \] where βλ is a basis for Vλ. Since the T-eigenspaces intersect trivially, β is linearly independent. Since every element in V is a sum of T-eigenvectors, β is a basis for V. Since the elements in β = { bi } are L-eigenvectors, ⟦T⟧β = diag(c ₁, c ₂, … , cn), where T(bi) = ci bi, for ci in 𝔽. This shows that condition (c) implies condition (a) and thus completes the proof.
- Anton, Howard (2005), Elementary Linear Algebra (Applications Version) (9th ed.), Wiley International
- Beezer, R.A., A First Course in Linear Algebra, 2017.
- Fitzpatrick, S., Linear Algebra: A second course, featuring proofs and Python. 2023.